



アクセス集中などによる高負荷が原因で障害が発生することがあります。対策として負荷テストを活用いただくケースが多くありますが、その目標設定の仕方には注意が必要です。
「高負荷障害の再発防止」という目標設定には要注意
「高負荷障害の対策を実施する」という目的で負荷テストを実施する場合、目標設定も同様のものにしてしまうケースが見受けられます。そのような場合、テスト実施者とサービス提供者の間に認識のずれが発生します。
| 立ち位置 | 期待 |
|---|---|
| サービス提供者 | サービスからみて、同規模のアクセス集中があった場合を想定した対策を実施する |
| テスト実施者 | システムからみて、過去と同等の負荷が発生した場合を想定した対策を実施する |
大きな違いは、視点の違いです。
サービス提供者はサービスとしての再発防止を考えます。たとえば同規模のイベントを実施した場合に再発しないようにしたい。というような視点です。
一方、テスト実施者はシステムに対して同規模のアクセスが来た場合に再発しないようにする。という視点で考えます。
視点が異なったまま進めると、最悪の場合、高負荷障害が再発し、認識の違いからトラブルに発展することもあります。
そのようなことを避けるために、高負荷障害の対策を実施する場合は次のことを双方が認識することが重要です。
- ログ等から本来のアクセス規模を確認することは困難
- ボトルネックは次から次へと発生する
それを踏まえて、次のような目標設定を行うように気を付けましょう。
- ボトルネックを〇個解消させる
- 性能を〇倍まで引き上げる
- 特定条件の元で最大限性能を引き上げる
共通認識すべきこと
アクセス集中などの高負荷に起因する障害の対策は不確実性が非常に高いものとなります。そのため、共通認識すべきことは次の2点です。
- ログ等から本来のアクセス規模を確認することは困難
- ボトルネックは次から次へと発生する
ログ等から本来のアクセス規模を確認することは困難
対策をするにあたって、ログの調査をすることは非常に重要です。しかしながら、どのくらいのアクセスが来た結果として高負荷障害につながったか。それをログ等の調査から確認することは困難です。わかることは、現状のシステム全体のキャパシティで受けられた限界値のみとなります。
通常アクセスの規模を確認する方法としては、GoogleAnalyticsなどのアクセス解析ツールやアクセスログ等を利用します。通常時は問題なく確認が可能ですが、高負荷時には確認が難しくなります。
なぜなら、アクセス解析ツールやアクセスログはその仕組み上、正常に処理されたもののみを記録するツールだからです。GoogleAnalyticsは画面表示がされた場合に埋め込まれたタグがアクセスの情報を送ることで集計可能になっています。アクセスログもサーバ上へアクセスが届き、何らかの処理が完了することで出力されます。
しかし、高負荷による障害が発生する場合には、インフラ側で接続数超過などで受付ができない状態になります。その結果、アクセスした人の処理はタイムアウトし、はブラウザ標準のエラー画面が出力されることになります。当然アクセスログへの出力はなく、GoogleAnalyticsへの集計も行われません。仮に行われていたとしても、通常時とは異なり、再読み込み(F5)連打をされていたり、なんとかつなげようと同一ユーザがスマホやPCなどの複数端末からアクセスされている可能性もあります。
つまり、アクセス解析ツールやアクセスログからわかることは、最大でもシステム全体で対応しきれた限界の情報であって、そのタイミングのアクセスの規模ではないのです。
そのため、同時アクセス〇〇に耐えることができれば問題ない!という具体的根拠を数値化するのは非常に困難になります。
参考までに、簡単な実験をしてみた結果をご覧ください。下の図は、同一の条件で別のシステムへアクセスした場合のアクセスログをグラフ化したものです。チューニング前後で条件は変えておらず、同時接続数300人でアクセスした場合のものとなります。
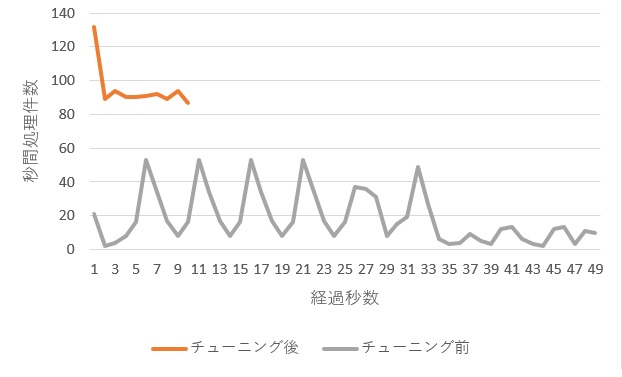
規模は同一でも、システムの性能によってアクセスログへの記録のされかたは異なる
チューニング前のグラフでは秒間60件以下のログしか記録されていないことに対して、チューニング後では最大130件のアクセスが記録されています。同一条件でアクセスしているにもかかわらず、ログへの出力件数は大きく異なります。
ボトルネックは次から次へと発生する
システムの性能が頭打ちになる原因をボトルネックといいます。高負荷の障害を引き起こす原因と言い換えることもできます。ボトルネックには次のような特徴があります。
- システムの限界値を決める
- 解消させると、システムの限界性能が向上する
- 解消されないと、システムの限界性能は向上しない
- 解消させると、次のボトルネックが発生する
高負荷障害の対策をするためには、ボトルネックを見つけることが非常に重要になります。
ボトルネックは現状を調査することで、ある程度当たりを付けることができます。しかし、注意しなければならないのは、負荷テスト実施前に次のことがわからないということです。
- ボトルネック解消後の性能向上効果
- ボトルネック解消後に発生するボトルネック箇所
つまり、確認しているボトルネックを解消させることで、非常に大きな効果がある可能性もあれば、それほど効果が出ない可能性もあるということです。そのため、ボトルネック解消=高負荷対策完了ということにはならない可能性があり、結果に対する認識の齟齬につながります。
好ましい目標は行動指標で設定
高負荷障害の再発防止は、アクセス規模など不確実なことが多いため解決にコミットできるものではありません。
不確実性が高い結果指標ではなく、コミットできる行動指標を目標値と設定し、少しづつ最終目的の再発防止に近づくアプローチが重要となります。
具体的に認識齟齬がないような行動し表の目標値には次のようなものがあります。
- ボトルネックを〇個解消させる
- 性能を〇倍まで引き上げる
- 特定条件の元で最大限性能を引き上げる
ボトルネックを〇個解消させる
ボトルネックを解消させる数を目標値とすることで、認識の齟齬が生まれにくいものにすることができます。
システムが次にどこがボトルネックとなるかを把握することは安定稼働させるうえで非常に有意義です。そのため、最低でも2個以上の値を設定しておくことをお勧めします。
性能を〇倍まで引き上げる
性能(以下、スループット)を〇倍まで引き上げるという目標値も認識の違いが生まれにくい指標です。
現状のスループットを測定し、ボトルネックを次から次へと解消していくことで目標のスループットへ到達することを目標とします。
注意点としては、目標到達までにボトルネックをいくつ解消する必要があるかわからない点です。場合によっては到達しない可能性もあります。その点を考慮し、ボトルネックの解消は最大5回まで。等の条件を付けておくことがお勧めです。
特定条件の元で最大限性能を引き上げる
「現状のインフラ構成で可能な限り性能を引き上げる」といようなケースも多くあります。
ボトルネックがスロークエリとして見えている場合などは、インフラ拡張はせずにシステムとミドルウェア設定で可能な限りの対策をすることがよくあります。インフラ拡張を行うと月額費用に跳ね返ってくるため、まずはスポット費用で対応できる部分を対応し、それでも問題が発生する場合はインフラ拡張を視野に入れていく形で進めていきます。
反対にシステム開発業者との保守が切れているので、「システムに手を入れずに可能な限り性能を引き上げたい」という要望を受けることもあります。しかし、システムのキャパシティはデータ量に応じて2次曲線で悪化していくことが多いため、うまくいかないケースが多い印象です。
まとめ
この記事では、高負荷障害の対策をする場合の注意点をまとめました。
高負荷障害の対策は不確実性が非常に高いため、「高負荷障害の再発防止」という結果指標は目標には適しません。その代わり、「ボトルネックを〇個解消させる」などの行動指標を設定し、少しづつでも着実に再発防止に向けて進んでいくことが重要になります。
参考.
全体的な負荷テストの進め方が気になる方は、「負荷テストの進め方」をご覧ください。