



クラウド全盛の時代となり、インフラ環境を短時間かつ低コストで拡大縮小できるようになりました。その恩恵として、AWSは「事前のキャパシティ予測は不要」と発信しています。
必要に応じてリソースの増減を行うことができるので、最大のインフラ容量を予測する必要がなくなります。アプリケーションの導入に先立ってキャパシティを決めてしまうと、高額で無駄なリソースの発生や機能が制限されたりします。クラウドなら、必要に応じてアクセスしリソースの調整やスケールアップやスケールダウンの実行をわずか数分で行うことができるため、そのような問題が発生する心配がありません
抜粋 https://aws.amazon.com/jp/what-is-cloud-computing/
実は、「事前のキャパシティ予測が不要」なクラウド時代では「負荷テストの重要性」がますます高まっています。しかしながら、「キャパシティ予測が不要=負荷テストは不要」という誤解が多く、キャパシティに関する問題が多く発生しているのが現状です。
システム全体のキャパシティは何で決まるのか
システム全体のキャパシティは、インフラとアプリケーションの組み合わせによって決まります。
- システム全体のキャパシティ=インフラ×アプリケーション
インフラとはサーバやネットワーク機器、回線等の動作環境を指します。アプリケーションとは、利用しているフレームワークや独自に実装したロジック、テーブル定義などです。
この記事では、システム全体のキャパシティについて解説し、「負荷テストは不要」という誤解を解いていきます。
インフラのキャパシティ特性
インフラのキャパシティ特性は、「ハードウェア」と「ミドルウェア設定」に分解することが可能です。
- インフラ=ハードウェア×ミドルウェア設定
ハードウェア
本記事で扱うハードウェアは、CPUやメモリなどのサーバスペックを指します。また、サーバ台数なども含みます。
ハードウェアは、増強をすることで一次曲線的にキャパシティが上昇します。たとえば、「CPU2コア/メモリ2GB」を「CPU4コア/メモリ4GB」にすれば2倍。1台を3台にすれば3倍という具合です。
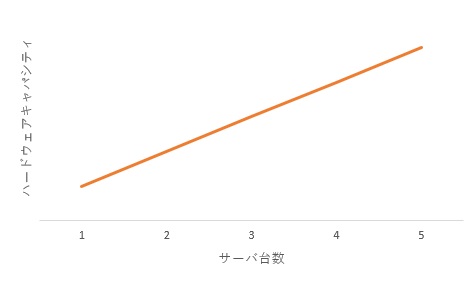
ハードウェアのキャパシティ特性は一次曲線
クラウドのスケールメリットを最も享受できるのが、このハードウェア部分にあたります。過去はメモリ追加のためには物理的なメモリの調達を行い、サーバを停止させメモリ追加をする必要があったため、追加までに数日~数週間かかることもありました。クラウドではコントロールパネルから設定変更するだけなので、数分で対応することができます。
一定期間たったら元の設定に戻すことも簡単なため、この数分や一時的なスペックアップ費用のために負荷テストをするのは確かに非合理的です。
ミドルウェア設定
スペックアップによるキャパシティ向上を阻害する要因が「ミドルウェア設定」です。
たとえば、DBのメモリ使用量の上限値を2GBとしていた場合、16GBのメモリを搭載していても使えるメモリは2GBとなります。また、最大接続数を極端に低くしていると、CPUを使い切ることはできません。
ミドルウェア設定がリミッターとなってしまっているのです。
理想としては、16GBのメモリが搭載されていれば16GBを、4vCPUのCPUであれば4vCPUを使い切れることです。そのためには、適切なミドルウェア設定を行い、各ハードウェアのキャパシティを使いきれる状態にすることが求められます。
このミドルウェア設定が適切にされていない場合は、「スペックアップをしても効果がない」「スケールアウトしても効果が薄い」という状態になります。
アプリケーションのキャパシティ特性
アプリケーションのキャパシティ特性は「データ量」と「ロジック」に分解することが可能です。
- アプリケーション=データ量×ロジック
データ量
性能に関する問題の発生パターンは2種類あります。
1) ローンチ直後
2) サービスローンチ後しばらくしてから徐々に顕在化
1)の場合は、ローンチ直後特有の突発的なアクセス集中などが原因となることが多いため、人気サービスであれば事前に負荷テストを事前に実施しているケースが多いようです。
問題は2)の場合です。リリース後しばらくしてから問題が発生する原因は、データ量にあります。利用するうちにデータが蓄積されていき、徐々に性能に問題を発生させるのです。アプリケーションの改修も行っていないのに、ある日突然性能問題が発生するのはこのケースとなります。
ロジック
データ量の増加による問題を発生させないためには、極力データ量に依存させないロジックで実装する必要があります。
SQLであればインデックスを利用する。突合せの処理であれば2重ループではなくマッチング処理を行う等です。
たとえば、国語辞典で考えてみます。
インデックスとは、国語辞典の「あ」「か」「さ」などと書かれている部分になります。
「負荷テスト」を調べたいときは「ふ」と書かれている部分から調べ始めることで、大幅に時間の短縮が可能です。
国語辞典から10個の単語を探し出す(突合せ)ことを考えてみると、一番効率がいいのは、探す単語を50音順に並べ替えて、先頭から順番に探していく方法です。
国語辞典は当然50音順でソートされており、探す単語も50音順でソートされています。探す単語の先頭から順番に調べていくことで、国語辞典のページを戻ることなくすべての単語を探しだすことができます。
このような方法をマッチング処理といいます。
反対に一番効率が悪いのは、国語辞典および探す単語両方が一切ソートされていない状態です。
ソートされていない国語辞典から一つの単語を探すためには、すべての単語を順番に見ていく必要があります。単語が見つかったとしても、次の単語を探すのに再度一から探していく必要があります。
このような方法を2重ループといいます。
現実的には絶対にやらない方法ですが、アプリケーションでは手軽に実装できてしまうために結構な頻度で見かけます。
下記グラフは突合せの処理を2重ループで行った場合のデータ量と処理時間を表現したものです。横軸がデータ量、縦軸が処理時間となります。見てわかる通り、データ量の増加とともに、処理速度が急激に増えています。
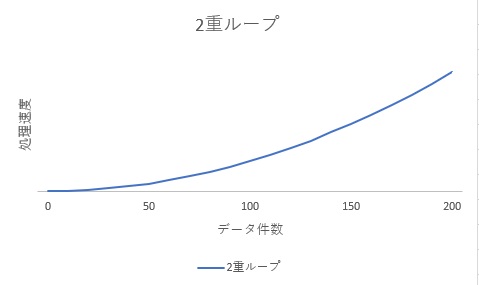
2重ループは二次曲線的に負荷上昇
2重ループ処理をマッチング処理に変更し、マッチング処理をオレンジ色の線で重ねてみました。
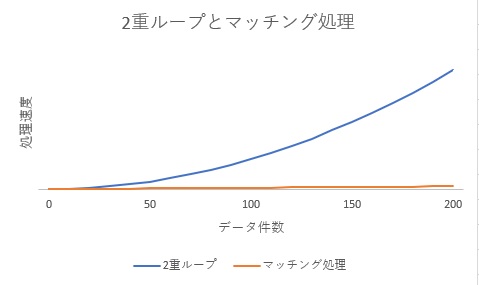
マッチング処理でデータ件数に依存しにくいロジックへ変更
2重ループでは指数関数的に処理時間が増加していましたが、マッチング処理にすることで1次関数的に増加するようになりました。速度もはるかに高速です。
データ量増加によるキャパシティをインフラで補うことは可能かもしれません。しかしながら、2次曲線的に性能が落ちていくので、それにあわせたインフラを用意することは、非常にコストパフォーマンスが悪いものとなります。
しかも、ロジックは早々に修正することが難しいため、長期にわたり高コストのインフラで運用せざるを得ないこととなります。
まとめ
本記事では、システムのキャパシティを次の要素で分解していきました。
- システム全体のキャパシティ=インフラ×アプリケーション
さらに、システム全体のキャパシティは、次のように書き換えることができます。
- システム全体のキャパシティ=ハードウェア×ミドルウェア設定×データ量×ロジック
それぞれの特徴を簡単にまとめると次のようになります。
| 要素 | 概要 | 負荷テストの関連性 |
|---|---|---|
| ハードウェア | 増やせば増やしただけキャパシティ向上 | クラウドの登場で短時間・低コストで拡張可能になったため、負荷テストでサイジングする必要性が低下 |
| ミドルウェア設定 | ハードウェアのリミッター役 | 負荷テストにより、具体的根拠をもとに設定が可能 |
| データ量 | リリース直後から増え続け、性能低下を引き起こす | データ量の想定シュミレーションによって、未来の性能低下を未然に防ぐことが可能 |
| ロジック | データ量に依存したロジックの場合、指数関数的に性能劣化 | 事前にデータ量に起因する問題を見つけ出し事前の対処が可能。結果として低コストなインフラ運用が可能 |
クラウドの登場で、ハードウェアに関するキャパシティ予測が不要となりました。しかし、ミドルウェア設定やデータ量に依存しないロジックの実装などは自らが実装していかなければなりません。そのための手段として負荷テストが有効になります。
適切な負荷テストをすることで、人気サイトになった場合も低コストなインフラで安定運用することが可能です。
システムのキャパシティについて理解し、サービスのリリース前や性能問題が顕在化する前に負荷テストを実施してみてください。
参考.
全体的な負荷テストの進め方が気になる方は、「負荷テストの進め方」をご覧ください。