



システムのキャパシティが不足しているときは、スケールアップやスケールアウトすることで手軽に追加キャパシティの確保が可能です。クラウドの利用で、簡易にサーバスペックアップや台数増加をさせることができるようになりました。
しかしながら、スケールアップやスケールアウトなどのインフラの拡張が効果的な場合と、そうではない場合があります。そこを踏まえずにインフラ拡張をしていくと、費用対効果が悪い対応となっていきます。
キャパシティの拡張を、アプリケーションチューニングとインフラ拡張の両面から考えることで、最大限の費用対効果を期待することができます。この記事では、その理由について考えていきます。
アプリケーションとインフラのキャパシティ
データ量や同時処理件数に依存するアプリケーションキャパシティ
アプリケーションのキャパシティは「処理内容」と「データ量」に大きく依存してきます。
下の図は、横軸がデータ量や負荷(アクセス)の大きさ、縦軸が必要なキャパシティを表しています。
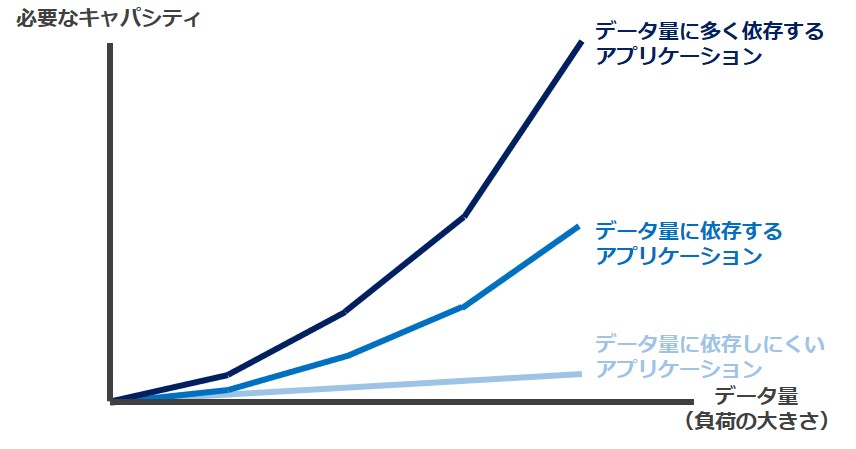
アプリケーションのキャパシティ
データ量に依存するため、リリース当初は件数が少なく目立った影響が出ることはありません。データ量の増加やアクセスの増加が進むと、アプリケーションを動かすために必要なキャパシティの差が、どんどん大きくなっていきます。しかも、指数関数的に必要なキャパシティが増えていくので、リリース後しばらくして、データが蓄積され、アクセスが増えると一気に問題が表面化します。
データ量に依存しやすいアプリケーションとは、2重ループやSQLのサブクエリ、フルスキャンなどが該当します。具体的な処理イメージでいうと、50音順にソートされていない辞書から、単語を10個見つけ出すような処理です。単語ごとに辞書を最初から引いていく必要があるため、登録単語が増えれば増えるだけ時間がかかります。
反対にデータ量に依存しにくい処理とは、50音順にソートされてインデックスがついた辞書から、50音順にソートした単語を10個見つけ出すようなものです。手戻りすることなく、最小限の手数で探すことが可能になります。
サーバ台数に依存するインフラキャパシティ
インフラのキャパシティの考え方は単純です。サーバスペックと台数によって直線的に増加します。1台で10のキャパシティを持っていれば、2台に増やすことで20のキャパシティを持つことになります。
※実際には、DISKIOやカーネル、ミドルウェア設定等の影響を受けますが、ここでは単純化させています
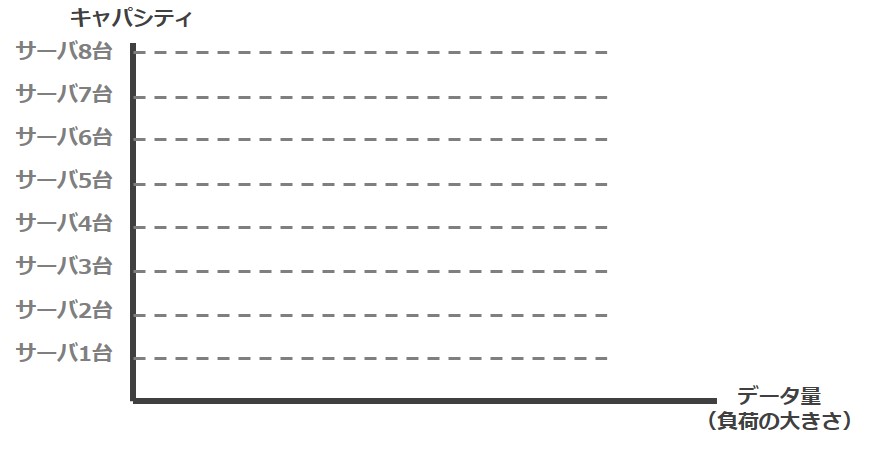
インフラのキャパシティ
シミュレーション
データ量に依存しやすいアプリケーションを例に、シュミレーションを行ってみます。
想定されるデータ量(負荷の大きさ)が現状のキャパシティを超える場合
サーバ1台で稼働しており、図の青線ようなキャパシティ特性を持っているとします。横軸は「データ量(負荷の大きさ)」縦軸は必要な(対応可能な)キャパシティとなります。
今後想定される「データ量(負荷の大きさ)」をA地点とします。サーバ1台で対応できるキャパシティは超えてきそうです。
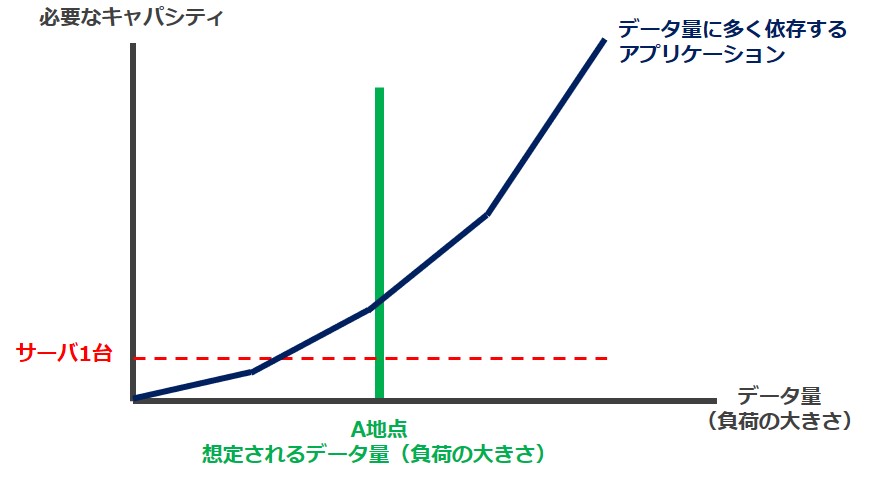
想定されるデータ量に必要なキャパシティ
インフラのみでチューニングする場合は、必要なキャパシティはサーバ台数が2台と3台の間に来るので、3台のサーバを用意する必要があります。
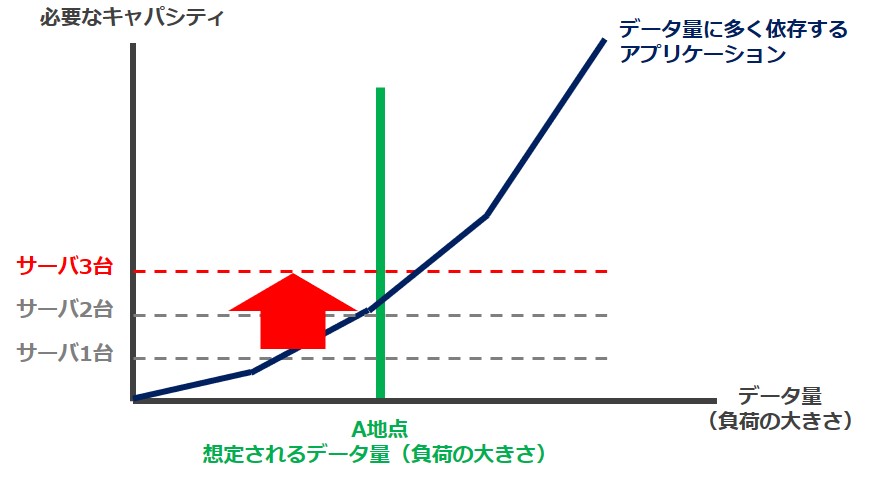
インフラ拡張のみで対応する場合
インフラではなく、アプリケーションをデータ量に依存しにくいものにチューニングできた場合は、サーバ1台にすることができる可能性があります。
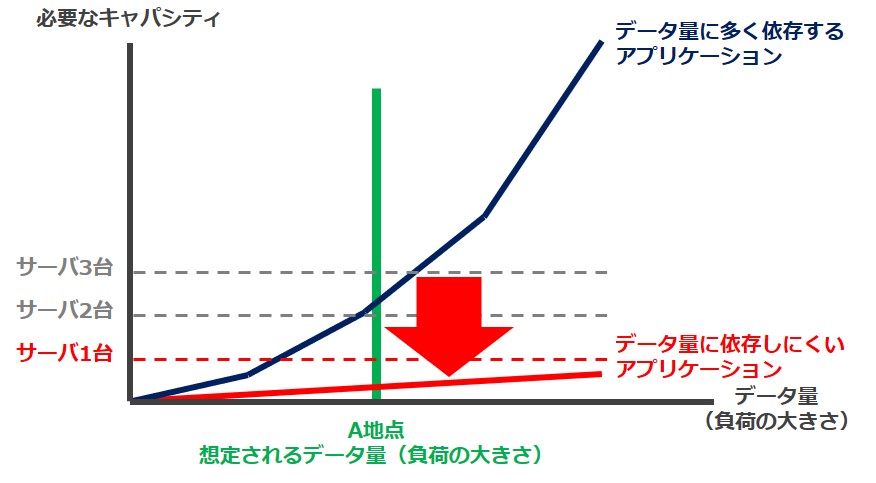
アプリケーションのみで対応する場合
アプリケーションのチューニングができた場合、サーバ1台で対応できなくても、サーバを2台にできるかもしれません。
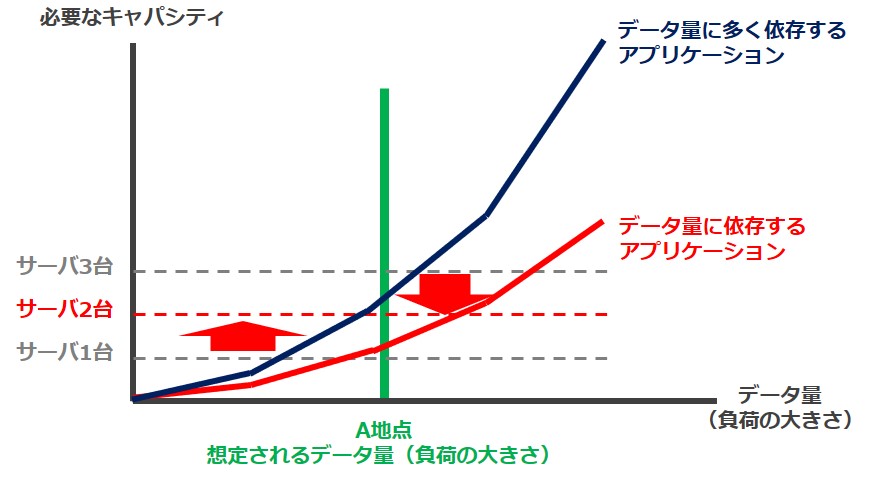
インフラ拡張とアプリケーションで対応する場合
想定されるデータ量が倍になった場合
A地点の対応が無事に終わり、将来的に想定されるデータ量が倍になった場合、つまりB地点になった場合のキャパシティについて考えてみます。
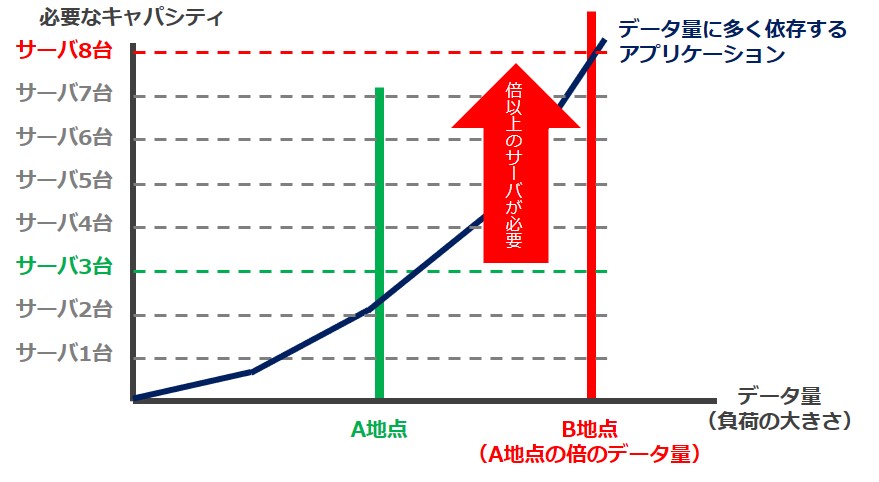
想定負荷が倍になると、インフラは倍以上必要に
データ量は倍なのでサーバ台数が倍の6台必要かといえばそうではありません。データ量に大きく依存してくるため、2.7倍となる8台のサーバが必要となります。
このように、アプリケーションによっては必要なサーバ台数はデータ量が増えるごとに指数関数的に増えていくため、インフラのみでキャパシティ拡張していくことは、非常にコストパフォーマンスが悪いものとなります。
まとめ
この記事では、アプリケーションとインフラのキャパシティ特性についてまとめました。
アプリケーションをデータ量に依存しにくいものにすることで、AWSをはじめとしたクラウドのメリットを活かすことが可能です。
反対にデータ量に大きく依存している場合、再現なくインフラをスケールさせる必要がでてくるため、非常にコストパフォーマンスが悪いシステムになってしまいます。
応急処置としてのスケールアップやアウトは積極的に行うべきですが、恒久的にはアプリケーション含めたシステムの全体最適化を考えてみましょう。